COVID-19 Resource Page
I started a COVID-19 resource page.
I started a COVID-19 resource page.
I couldn’t find a concise article about creating a Debian installer USB key with a writable file system, so here is my take. This assumes you have an available Linux system. Note that some old BIOSes might not happily boot USB drives created in this way.
You can also automate the installation. See: http://www.debian.org/releases/stable/amd64/apb.html.en. The preseed.cfg file should go into the root folder of the USB key. You can then change the syslinux.cfg file to:
default vmlinuz
append initrd=initrd.gz auto file=/hd-media/preseed.cfg locale=en_US console-keymaps-at/keymap=us
You now have a bootable USB key that you can also easily modify.
I am attending the USENIX security conference this week. Sessions are available online. Here are my notes from sessions that I found interesting (bold for extra):
Network Security in the Medium Term: 2061–2561 AD, Charles Stross
Stross is one of my favorite science fiction authors. The main direction of the talk was the future political importance of information security. This is due to the intrusiveness of future information breaches once lifelogging, bioinformatics and other very intimate technologies are adopted.
Fast and Precise Sanitizer Analysis with BEK, Pieter Hooimeijer, et al
Toward Secure Embedded Web Interfaces, Baptiste Gourdin, et al
Comprehensive Experimental Analyses of Automotive Attack Surfaces, Stephen Checkoway, et al
Privacy in the Age of Augmented Reality, Alessandro Acquisti, et al
Secure In-Band Wireless Pairing, Shyamnath Gollakota, et al
TRESOR Runs Encryption Securely Outside RAM, Tilo Müller and Felix C. Freiling:
A Study of Android Application Security, William Enck, et al
Permission Re-Delegation: Attacks and Defenses, Adrienne Porter Felt, et al
Telex: Anticensorship in the Network Infrastructure, Eric Wustrow, et al
Three Researchers, Five Conjectures: An Empirical Analysis of TOM-Skype Censorship and Surveillance, Jeffrey Knockel, et al
This is a somewhat technical article and assumes knowledge of Android and Linux.
Just got a Nexus S, and had some issues moving my contact list from my old phone. So I decided to write this up.
You have two options:
* If you come from a ROM that allows export to SD, just use Import/Export to USB storage, copy the file over, then import it
* Option #2 would have been to use Titanium Backup. However, it doesn’t seem to work right for restoring on the Nexus S (yet).
* Otherwise, you can copy the contacts2.db file. Of course, you have to root your target phone first. Then copy the db file to the sdcard.
As root, do (assuming standard layout):
cd /data/data/com.android.providers.contacts/databases
rm contacts2.db
cat /sdcard/contacts2.db > contacts2.db
chmod 660 contacts2.db
ls -l .. # see who owns this directory
chown
You might have to restart your phone for the contacts to be re-read.
Zyvex can now build atomically precise 3-D structures from silicon. That’s a nano equivalent to the MakerBot.
Arbitrary structures can be used to build templates and tools that can further build other tools, bootstrapping a new industry.
A very insightful talk about how we lost our freedom and how to regain it
You can also read the full transcript linked from there.
Here are some background pointers:
A list of projects in this space. The Diaspora project is listed under “deployable on commodity webhosting”. I was under the impression that they are actually more of a p2p application.
A set of ideas for this space on the GNU Social wiki.
Adriana Lukas talks about the user-controlled web and the mine project. (She coins a fun acronym: Relationships on Individuals’ Own Terms – RIOT. )
(flash video removed June 2016)
There seems to be quite a bit of activity with 20-30 projects, but the efforts are fragmented. Different projects have different goals and approaches. Some focus on a piece of the user experience and others focus on technology. For example, the Mine! project is a technology piece focused on rich sharing of data (including links, photos) with strong user control. OneSocialWeb is focused on messaging. With Elgg you can create social networks – but it’s not really user controlled.
Diversity is great, but one or two well-thought out efforts need to win. Critical mass is a must in order to win in this space.
I’m pretty excited about the Diaspora project generating a groundswell of support. They managed to raise $170K in two weeks through kickstarter (they asked for $10K).
Why am I excited? I’ve written before about walled gardens and user controlled Internet apps. It is crucial that we invert the control structure of the web if we want to be in control of our destiny.
There are some critical challenges that a user-controlled system must face:
I can’t wait to see what the first prototype looks like.
There are some additional projects along these lines that are worth a look and are actually further along:
Maybe none of these will make it. But the $170K is a signal – that people care about this.
Sanity prevails in federal court! News at 11.
As a Cryonics member, I became interested in a new initiative to fixate the brain in a plastic medium: brainpreservation.org
Would be excellent to have a high fidelity preservation procedure that doesn’t require maintenance (such as liquid nitrogen in the case of Cryonics).
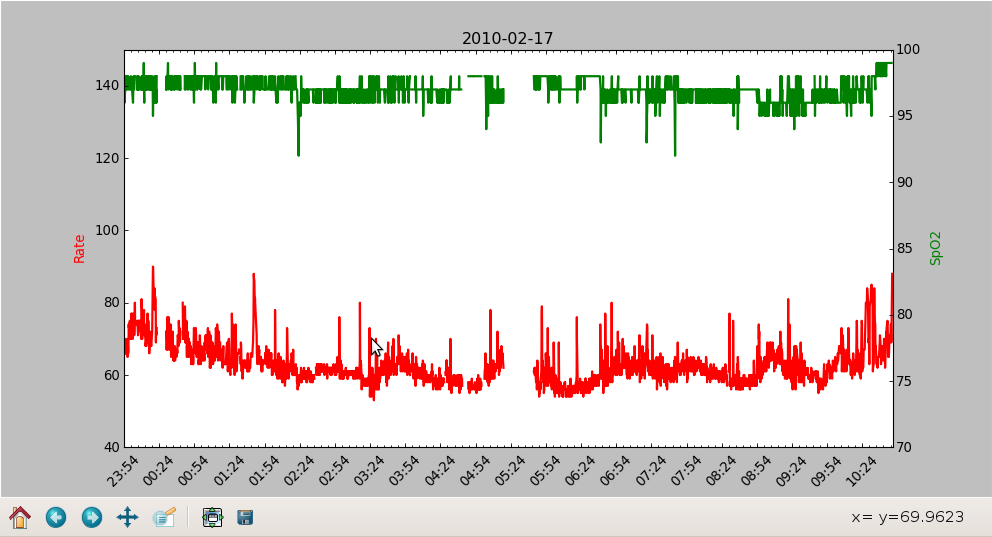
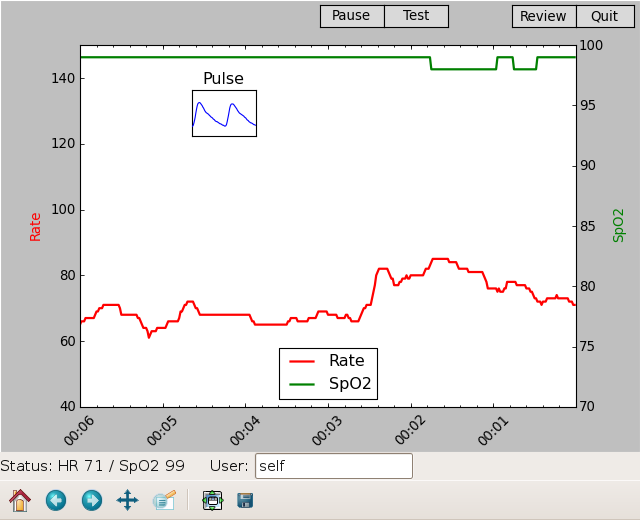
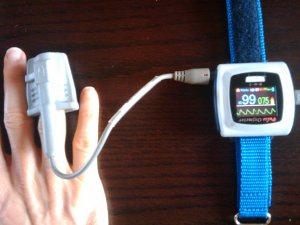
After attending a couple of Quantified Self meetups, I was inspired to quantify various aspects of myself and my life. For example, I was wondering if I am breathing well while I sleep, since I have been waking up tired on occasion.
I bought the Contec CMS50-F oximeter from here.
The software that comes with the CMS50 could be more reliable and user-friendly, and only runs on Windows. I ended up spending a day reverse engineering the USB protocol and writing a Python program to acquire and graph the data. The software is on Gitorious.
Here are some of the charts you can get:
Noah Hutton’s company Couple 3 Films has released year 1 of a 10 year documentary project documenting the Blue Brain project. The project includes Henry Markham’s work on reverse engineering the brain, scaling up from rodents to humans by 2010.
The work is funded by the Swiss government.
Life Technologies announces $3,000 marginal cost (later this year) for sequencing complete human genomes. This is after Illumina announced the same for $10,000 (now). So a $1,000 genome early next year?
Here comes personalized medicine.
I’ve been asked to outline specific scenarios after I posted a previous entry on the Google’s network compromise. Here are some, from most serious to least serious:
How would multiple independent auditors help? If the auditors can verify that a binary was produced from certain source, the build host compromise would be much harder, since the altered binary would not signed by the uncompromised auditors. Similarly, a signing key compromise, if it is limited to a subset of auditors, would fail to get a full set of signatures on the altered package.
Source repository compromise and Insider injection of security holes would be more difficult to detect for subtle exploits, but again, multiple entities looking at the code increases the chances that the alteration would be caught.
(Note: verification that a certain binary was produced from certain source code requires a deterministic build system. Although such a system is relatively straightforward to implement, I have not run across one before I implemented Gitian. I did find mention of it by Conifer Systems.)
CNet reports on Ponemon institute’s survey showing a doubling of data breach incidents.
Average cost per record in the surveyed group is around $200.
Operation Aurora (Google’s compromise by China) highlights the possibility that software distributions may be targeted for code injection by malicious parties. If Apple, Microsoft or a linux distributors are compromised, a large percentage of individuals, businesses and governments could be consequentially compromised when they install software updates.
One way to mitigate such a risk is to have multiple independent security auditors sign software distributions. This is more likely to be successful in an open-source environment, where source is available and can easily be inspected. I started such an initiative in late 2009 – Gitian.org.
Alex and I got nasal H1N1 vaccines on Tue. I felt tired on Wed and Alex has a sore throat. Nasal is live-attenuated instead of dead virus.
Apparently symptoms are more likely with the nasal. On the up-side – no preservatives!
No, the nasal-spray flu vaccine LAIV (FluMist) does not contain thimerosal or any other preservative.
The Register tells us that Amazon will auction their excess capacity. We’re a couple of steps away from computation becoming a liquid commodity. The next step is for a couple of additional providers to arise (Google?). The step after that is for the APIs to be brought in sync by the providers or by a third party intermediary.
Peter Thiel writes regarding the failure of Democracy to preserve freedom and some possible technofix strategies. He includes are thoughts about creating freedom in Cyberspace, Outer space or on the high seas. I think it would be interesting to build certain distributed Internet apps that could change the dynamics of freedom, including reputation systems, gifting/barter systems and user-controlled Internet apps.
[Read more →]
I’ve been thinking about what we learned about freedom from the open-source movement.
I think one of the more important benefits of freedom is that it is generative. You can glue things together in ways that create completely new things. For example, you can take the Internet, existing computers and the ability to write software (originally the Mosaic browser) and create a whole new ecosystem – the World Wide Web.
What if you didn’t have the freedom to transmit arbitrary data on wires? You’d have the telco monopoly and no Internet. If you couldn’t talk to anybody you want? You’d get the original walled-garden AOL. If you couldn’t write arbitrary software?
But there’s nothing specific to software in this lesson. What if you couldn’t freely associate? If you couldn’t invest in arbitrary ideas? If someone else made the decisions for you?
Another question is how much could we go beyond the current state of affairs. I think we could have significantly more freedom in technology and obtain much richer outcomes.
For example, if reputations systems were not stuck in walled gardens, such as eBay and Amazon seller ratings, we could have a global reputation system. Such a system will be immensely more useful, since it could be used to guide us in every interaction rather than just the current 1%. I would guess that such a system could guide you to interesting content and interaction with uncanny accuracy. Such a system would have to be decentralized and user-controlled to protect the users’ interests.
Another promising direction is the Google Android phone OS. If you buy one of the unlocked ones (also known as dev phones), you can re-compile and install the OS and any applications you want. Google maps is one mobile killer app, but there will be more, and I would guess the truly groundbreaking ones will not pass the iPhone store gateway keepers. (see here, here and many others).
I sometime pay a price for being an early adopter and eschewing closed solutions. Yes, the iPhone is very slick and music from the iTunes store was tempting even when it was all DRM. But I think in the long term open solutions will be much more valuable. The original AOL was nice for the time, but it’s dead now.